Job Metrics Reporting
Overview of the Job Metrics Dashboard for Slurm
Job Metrics Reporting
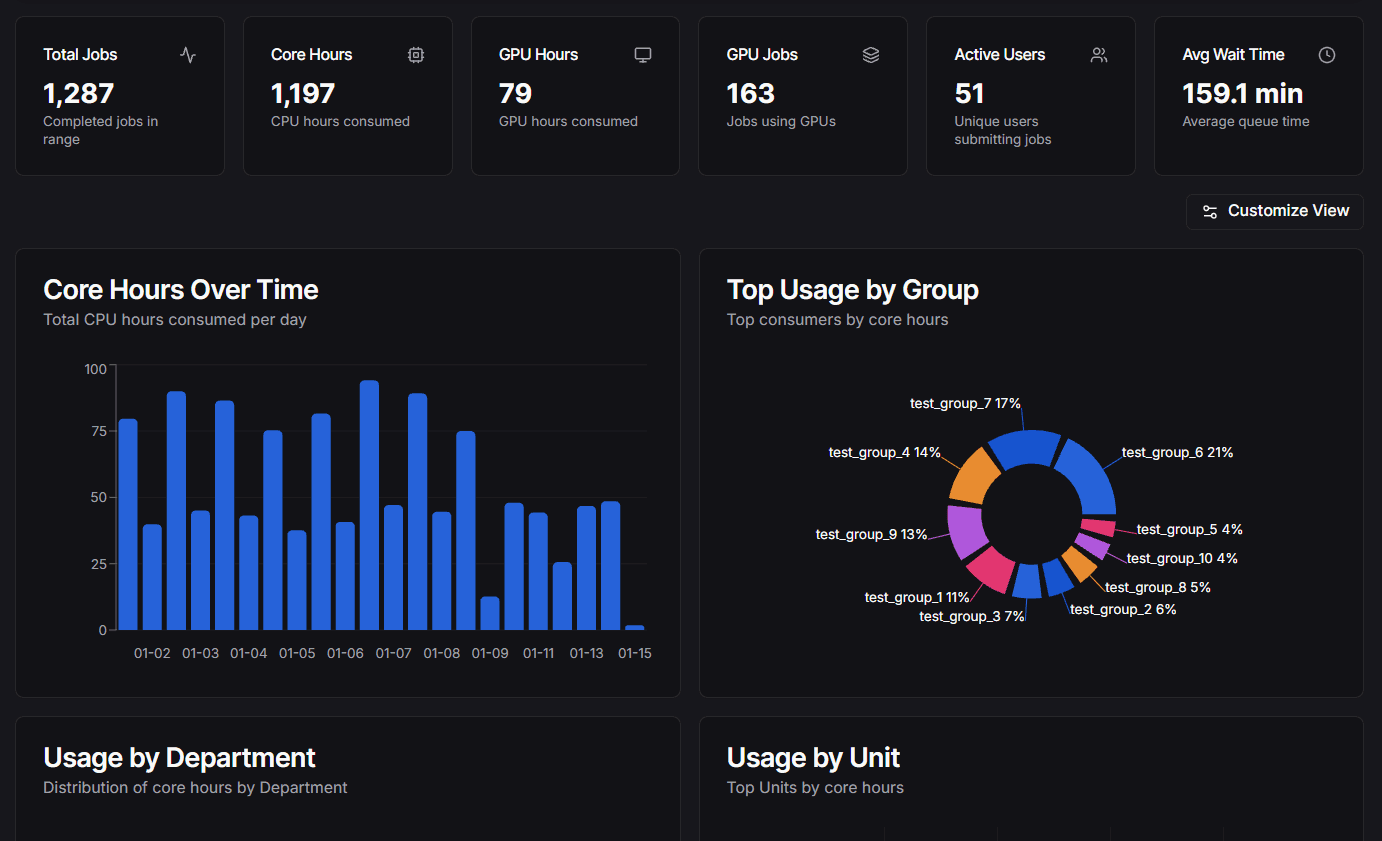
The Job Metrics Dashboard provides a comprehensive view of job details tailored specifically for Slurm. It serves as a lightweight analytics tool to provide insights into cluster usage, efficiency, and user activity.
This feature allows administrators and users to visualize job metrics, analyze historical data, and generate reports based on Slurm job accounting data collected by the Slurm History Ingestor.
Getting Started
- Install the ingestor and database: Installation
- Configure the dashboard and environment variables: Configuration
- Set up the ingestor service and its options: Go Scraper
- Define organization hierarchy and mappings: Organization Hierarchy
Key Features
- Job Details: Detailed metrics for individual jobs including wait times and exit codes.
- Cluster Usage: Overview of core hours, job counts, and wait times over time.
- User Activity: Insights into active users, groups, and account usage.
- Visualizations: Graphs and charts for core hours over time, usage by group, and more.
Architecture
The system consists of two main parts:
- Slurm History Ingestor (Go Scraper): A standalone service that fetches job history using sacct (primary method) or the Slurm REST API (fallback) and stores it in a PostgreSQL database.
- Dashboard Plugin: A frontend component within this Next.js application that queries the database to visualize the metrics.
What Gets Populated Where
The Slurm History Ingestor only syncs job data from Slurm. Other data sources are populated separately:
| Data | Source | How It's Populated |
|---|---|---|
Job history (job_history) | Slurm (sacct/API) | Automatically by the Go ingestor |
Users (users) | Slurm (sacct/API) | Automatically by the Go ingestor |
Accounts (accounts) | Slurm (sacct/API) | Automatically by the Go ingestor |
Organizations (organizations) | Your institution | Imported via Admin page or CSV |
Account mappings (account_mappings) | Your institution | Imported via Admin page or CSV |
GPU metrics (job_gpu_metrics) | Prometheus/DCGM | Captured via POST /api/gpu endpoint |
Important:
The ingestor is intentionally focused only on Slurm job data. Organizational hierarchy is institution-specific metadata that must be imported separately. GPU metrics come from Prometheus, not Slurm.
Requirements
To enable the Job Metrics Dashboard, you need:
- Go Scraper: Installed and running on a host with
sacctaccess (recommended) or Slurm REST API access (fallback). See Go Scraper. - PostgreSQL Database: To store the collected metrics.
- Plugin Configuration: Enable the dashboard in your
.env. See Configuration.
Please refer to the Installation and Configuration guides for detailed setup instructions.
Hierarchy Configuration
The job metrics dashboard uses organizational hierarchy to group and filter data by department, college, or other organizational units. This is institution-specific metadata that is not populated by the Slurm History Ingestor — it must be configured separately via the Admin dashboard or CSV import.
For full details on setting up, importing, and managing your organizational hierarchy, see the Organization Hierarchy guide.